
Security operations centers (SOC) are incredibly noisy places. They experience hundreds of thousands of security alerts daily. 1% are urgent and very likely to be true attacks. 30% of alerts are false positives. The rest of 69% are either information, nonactionable, or take time to completely identify as false positives or true positives. Either tweaking them which could generate more false positives or ignoring them which put the company at risk. Despite every alert coming with a default score, they are not well prioritized nor calculated based on your context, therefore wasting resources on trivial risks and slowing down responses to important risks.
Risk-based Alerting
Instead of looking at atomic alerts, let’s look at aggregate risks over a group of alerts and alert over them once the aggregated risk exceeds thresholds. According to the famous risk formula:
RISK = probability x loss
On the Probability side, here are a few factors to measure:
- Which stage are these in MITRE ATT&CK Matrix
- Does it progress like an attack kill chain?
- How confident are these security detections?
- What is the historical false positives rate?
- How many vulnerabilities on this machine are exploitable?
- Are they new entities?
One the Loss side
- How critical is this user? Admin or Normal?
- How important is this machine? Domain controller or Critical database?
- How far are they away from critical datasets?
Quantify the risks
Once laying down the affecting factors, you can start to qualify them. For example:
- Early stage detections got a score of 1 and late stage detections got a score of 10
- The normal machine got a score of 1, Domain controller got a score of 10
- Etc.
Eventually, summarize all factor scores in probability and all factor scores for loss. The multiply of both is the final risk score.
Alerting
Set up a threshold for alerting based on the final risks.
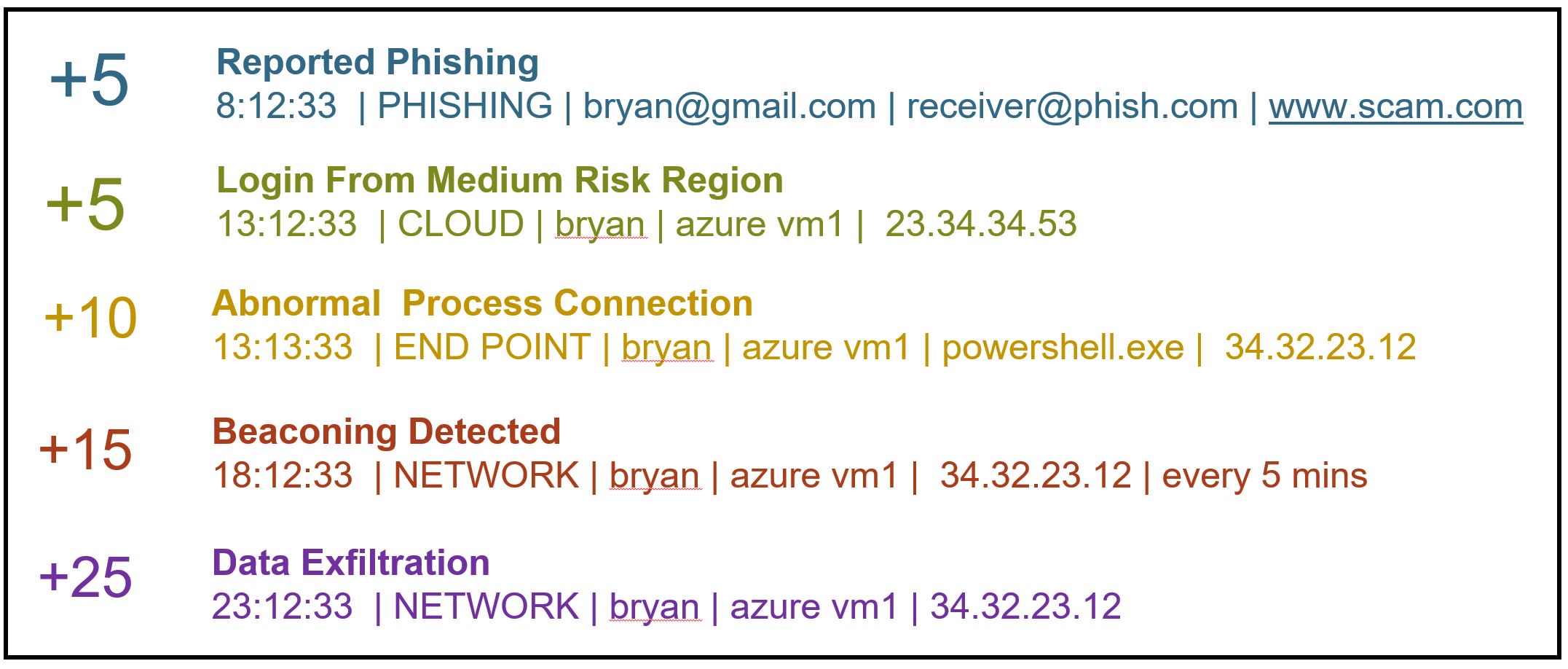
Benefits
- Save time on some investigation because alerts are now correlated and you now have more context
- Reduce false positives in atomic alerts by only alerting on aggregated risks
- Detect slow and attacks since it aggregates risks over time
Reality Check:
RBA does save time as the fact that it correlates alerts. The very tricky part is that you now have to tune all those factors and decide which factor is important that requires continuous tuning. And these scores are very arbitrary. Without normalization, it is hard to compare one-to-one with one threshold value. (think about comparing apple vs bear). Normalization is a learning and fine-tuning process that takes time. Besides, legit users/machines still do weird stuff which can not be ruled out by RBA. For example, legit software triggers Mimikatz or uses encoded Powershell. In RBA, all these will trigger high critical alerts and bump up the scores.
Why does this happen?
It is because your risk score is not accurate.
The aggregated risk score is based on a simple aggregation of static factors. However, there are lots of dynamic factors that could make risky stuff less risky in your environment. For example, a detection turns out to be more likely noisy; something that is less uncommon in your environment, etc. These types of dynamic changing factors need to be continuously learned/updated to mitigate the pitfalls of RBA and set you back in the right direction.
