
A malicious website is a site that attempts to install malware on your computer and may attempt to install onto your devices. Usually it requires permissions on your side, however, in the case of a drive-by downloads, the website will attempt to install software without your permissions. In many times, malicious websites often look like legitimate websites. What’s more, your anti-virus software might not be able to detect it because hackers deliberately program it in such a way that it is difficult for anti-virus software to detect.
To avoid this, is it possible to detect a suspicious website using machine learning?
Let us look at a dataset on Kaggle 1 and see if we can use the power of machine learning to detect malicious websites.
Table of Contents
1) Descriptive Statistics
2) Exploratory data analysis and data cleaning
3) Machine Learning
4) Summary
[showhide type="post"]from IPython.display import display
from IPython.display import HTML
import IPython.core.display as di # Example: di.display_html('<h3>%s:</h3>' % str, raw=True)
# This line will hide code by default when the notebook is exported as HTML
di.display_html('<script>jQuery(function() {if (jQuery("body.notebook_app").length == 0) { jQuery(".input_area").toggle(); jQuery(".prompt").toggle();}});</script>', raw=True)
# This line will add a button to toggle visibility of code blocks, for use with the HTML export version
di.display_html('''<button onclick="jQuery('.input_area').toggle(); jQuery('.prompt').toggle();">Toggle code</button>''', raw=True)
#Importing the required libraries
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import cross_val_predict, cross_val_score
from sklearn.metrics import confusion_matrix,classification_report,accuracy_score
from sklearn import metrics
%matplotlib inline
import warnings
warnings.filterwarnings("ignore")
#We will read the URL dataset and perform some EDA
df = pd.read_csv('dataset.csv')
[/showhide]
Descriptive Statistics
We have a labeled dataset consisting of websites and whether they are malicious or not. The websites are run through a feature generator which stores information of a website which runs in the network and application layer. The goal is to predict whether a website is malicious or not.
Using the features generated from the website is it possible to make use of machine learning to detect a malicious website?
| 0 | M0_109 | 16 | 7 | iso-8859-1 | nginx | 263.0 | None | None | 10/10/2015 18:21 | None | … | 0 | 2 | 700 | 9 | 10 | 1153 | 832 | 9 | 2.0 | 1 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | B0_2314 | 16 | 6 | UTF-8 | Apache/2.4.10 | 15087.0 | None | None | None | None | … | 7 | 4 | 1230 | 17 | 19 | 1265 | 1230 | 17 | 0.0 | 0 |
| 2 | B0_911 | 16 | 6 | us-ascii | Microsoft-HTTPAPI/2.0 | 324.0 | None | None | None | None | … | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0.0 | 0 |
| 3 | B0_113 | 17 | 6 | ISO-8859-1 | nginx | 162.0 | US | AK | 7/10/1997 4:00 | 12/09/2013 0:45 | … | 22 | 3 | 3812 | 39 | 37 | 18784 | 4380 | 39 | 8.0 | 0 |
| 4 | B0_403 | 17 | 6 | UTF-8 | None | 124140.0 | US | TX | 12/05/1996 0:00 | 11/04/2017 0:00 | … | 2 | 5 | 4278 | 61 | 62 | 129889 | 4586 | 61 | 4.0 | 0 |
5 rows × 21 columns
The dataset consists of URL, message along with the information whether a website is malicious or not.
Let us look at the description of major attributes in the dataset
• URL: anonymized URL which may or may not be malicious.
• URL_LENGTH: Indicates number of characters in the URL.
• NUMBER_SPECIAL_CHARACTERS: Indicates special characers in the URL.
• CHARSET: It indicates the character encoding standard and is a categorical variable.
• SERVER: It indicates the operative system of the server got from the packet response and is a categorical variable.
• CONTENT_LENGTH: It indicates the content size of HTTP header.
• WHOIS_COUNTRY: Using Whois API it indicates the Countries the server got a response and is a categorical variable.
• WHOIS_STATEPRO: Using Whois API it indicates the States the server got a response and is a categorical variable.
• WHOIS_REGDATE: It indicates the Whois server registration date.
• WHOIS_UPDATED_DATE: It indicates the last update date from the server analyzed.
• TCP_CONVERSATION_EXCHANGE: It indicates the number of TCP packets that were exchanged between the honeypot client and the server.
• DIST_REMOTE_TCP_PORT: It indicates the number of ports detected.
• REMOTE_IPS: It indicates the total number of IPs connected to honeypot client.
• APP_BYTES: It indicates the number of bytes transfered.
• SOURCE_APP_PACKETS: It indicates the packets sent from the honeypot to the server.
• REMOTE_APP_PACKETS: It indicates the packets received from the server.
• APP_PACKETS: It is the total number of IP packets generated during the communication between the honeypot and the server.
• DNS_QUERY_TIMES: It indicates the number of DNS packets generated during the communication between the honeypot and the server.
• TYPE: This is the outcome variable indicating whether the website is malicious or not.
Exploratory data analysis and Data cleaning
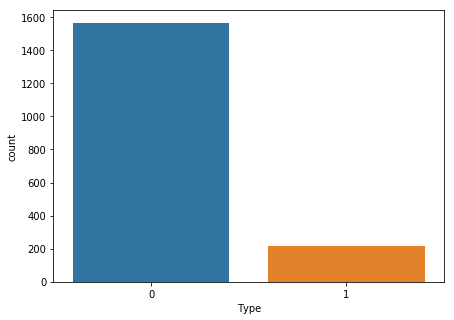
We can see most of the websites are benign while some are malicious. Let us look if there is a relationship between different attributes and the Type of the Website.
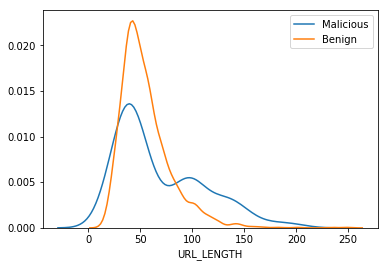
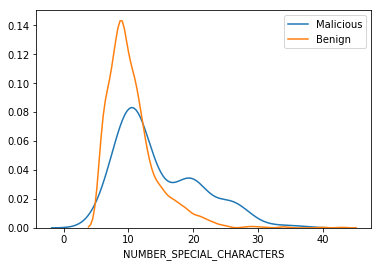
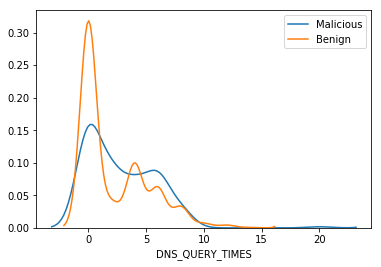
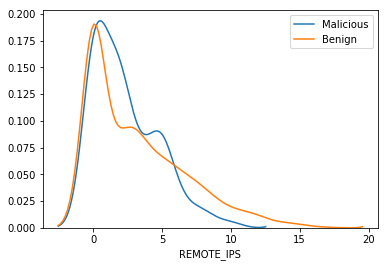
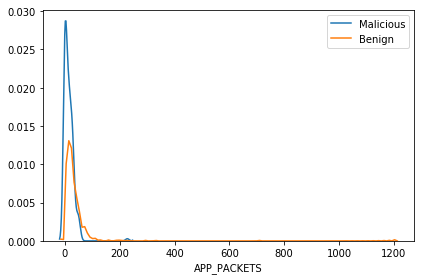
We can see that some of the attributes show a huge difference and these attributes can be a useful in identifying whether a website is malicious or not. This information may get modeled while training which could be used by our model to how risky is the website and if this is more than a certain threshold a user can be alerted before he/she proceeds to the website.
Hence we can see that depending upon the attributes the risks of getting infected can change!
Let us look at the attributes and the correlations using a corrplot, this can help in understanding the important attributes and avoiding multicollinearity.
<matplotlib.axes._subplots.AxesSubplot at 0x1e434c15518>
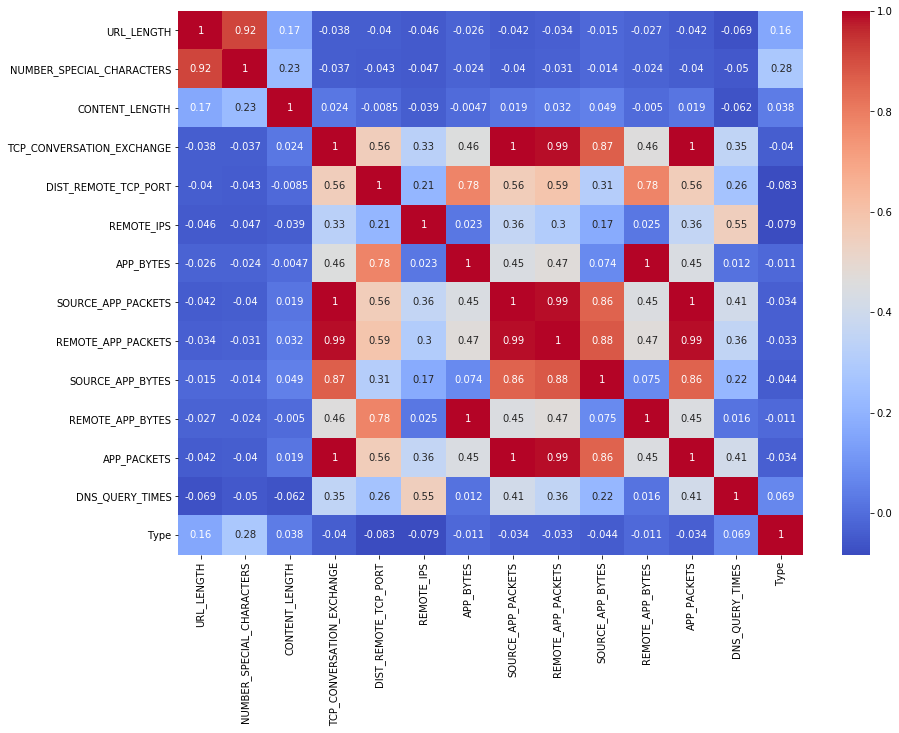
URL_LENGTH | NUMBER_SPECIAL_CHARACTERS | CONTENT_LENGTH | TCP_CONVERSATION_EXCHANGE | DIST_REMOTE_TCP_PORT | REMOTE_IPS | APP_BYTES | SOURCE_APP_PACKETS | REMOTE_APP_PACKETS | SOURCE_APP_BYTES | … | WHOIS_UPDATED_DATE–9/09/2015 0:00 | WHOIS_UPDATED_DATE–9/09/2015 20:47 | WHOIS_UPDATED_DATE–9/09/2016 0:00 | WHOIS_UPDATED_DATE–9/10/2015 0:00 | WHOIS_UPDATED_DATE–9/11/2015 0:00 | WHOIS_UPDATED_DATE–9/11/2016 0:00 | WHOIS_UPDATED_DATE–9/12/2015 0:00 | WHOIS_UPDATED_DATE–9/12/2015 14:43 | WHOIS_UPDATED_DATE–9/12/2016 0:00 | WHOIS_UPDATED_DATE–None | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 16 | 7 | 263.0 | 7 | 0 | 2 | 700 | 9 | 10 | 1153 | … | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 |
| 1 | 16 | 6 | 15087.0 | 17 | 7 | 4 | 1230 | 17 | 19 | 1265 | … | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 |
| 2 | 16 | 6 | 324.0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | … | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 |
| 3 | 17 | 6 | 162.0 | 31 | 22 | 3 | 3812 | 39 | 37 | 18784 | … | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 4 | 17 | 6 | 124140.0 | 57 | 2 | 5 | 4278 | 61 | 62 | 129889 | … | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
5 rows × 1978 columns
Categorical attributes can be handled using dummy variables as machine learning algorithms cannot understand anything which is not numeric.
Machine Learning
Let us make use of machine learning to predict whether a website is malicious or not.
By using random forest we can obtain feature importance which can help understanding the most important attributes.
Training Accuracy Score: 0.9983948635634029
Let us look at the predictions on the Test dataset.
Accuracy: 95.7%
precision recall f1-score support
0 0.95 1.00 0.98 462
1 0.98 0.70 0.82 73
micro avg 0.96 0.96 0.96 535
macro avg 0.97 0.85 0.90 535
weighted avg 0.96 0.96 0.95 535
We have achieved 95.33% accuracy in detecting whether a website is malicious or not.
Let us look at the AUC score
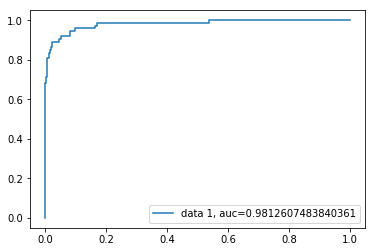
Based on the AUC score we can see that we have a very good model which can predict if a website is malicious or not.
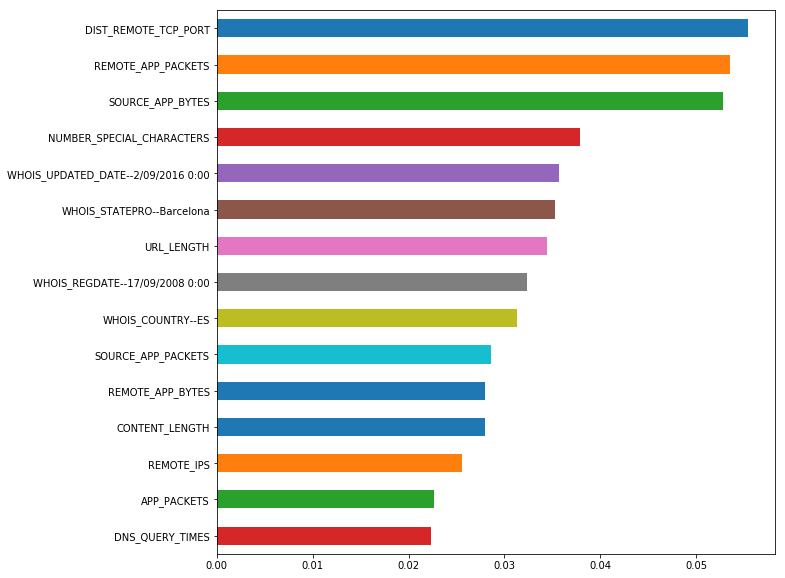
Let us look at the most important features.
('DIST_REMOTE_TCP_PORT', 0.05542248595112565)
('REMOTE_APP_PACKETS', 0.05350555875366626)
('SOURCE_APP_BYTES', 0.05278637609692167)
('NUMBER_SPECIAL_CHARACTERS', 0.03784767672080814)
('WHOIS_UPDATED_DATE--2/09/2016 0:00', 0.035669284782677904)
('WHOIS_STATEPRO--Barcelona', 0.03531835186890351)
('URL_LENGTH', 0.0343964152328995)
('WHOIS_REGDATE--17/09/2008 0:00', 0.03239780891591486)
('WHOIS_COUNTRY--ES', 0.03135052817134378)
('SOURCE_APP_PACKETS', 0.02854442611666951)
('REMOTE_APP_BYTES', 0.02801012481009961)
('CONTENT_LENGTH', 0.027931476567531185)
('REMOTE_IPS', 0.025523627035864523)
('APP_PACKETS', 0.022632579871355966)
('DNS_QUERY_TIMES', 0.022313662212124954)
Summary
We have performed analysis on the malicious websites dataset. We can see how a machine inteprets and learns from the features. Based on the differences in the featues it can classify whether the website is malicious or not.
By making use of machine learning we can train a model to identify whether a website is malicious or safe. This is useful as the model takes only url as an input and the model can generate other features and identify if the website is risky or not.
1. Data Source: https://archive.ics.uci.edu/ml/datasets/sms+spam+collection ↩
