
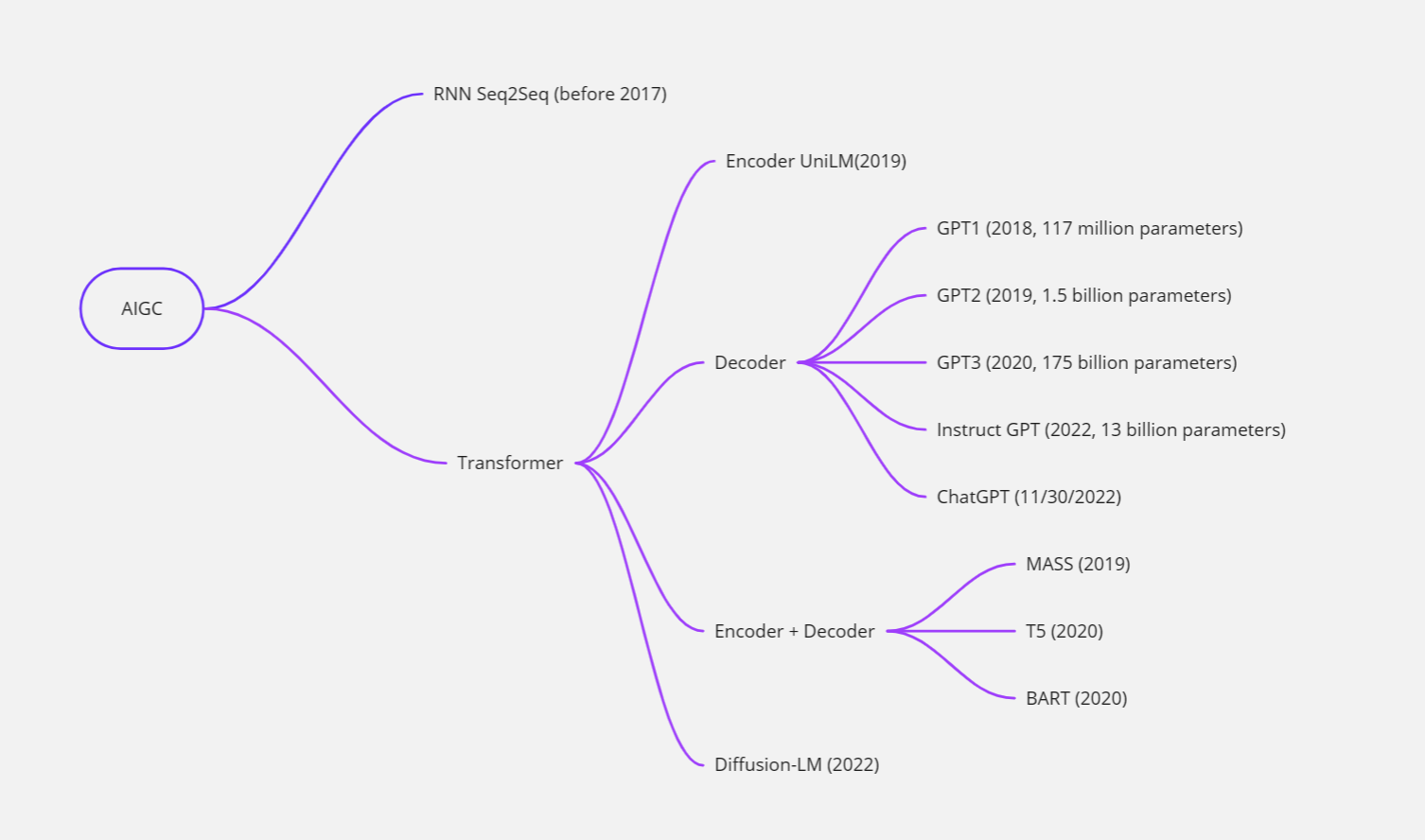
AIGC, or AI-generated Content, is a way of content creation using artificial intelligence and is considered a new type of content creation after PGC (Professionally-generated Content) and UGC (User-generated Content). AIGC is developing rapidly in many fields such as text, image, and audio/video, software development, and in recent years there are many creation experience platforms that focus on AIGC, where users can input a sentence to let AI synthesize a picture associated with the description, or more commonly, input a description of an article, or just the beginning of a story, and let AI finish the article for you. It has broad applications wherever writing or content creation is needed such as writing a financial report, developing code, or creating sales/marketing materials. It can help people understand and analyze complex information faster, thus helping them make better decisions and generate significant value. These visions of productivity improvement are becoming a reality thanks to the advancement of technology. We’ve summarized the development of AIGC technology in the following chart and will elaborate on them in the following blogs.
RNN Seq2Seq
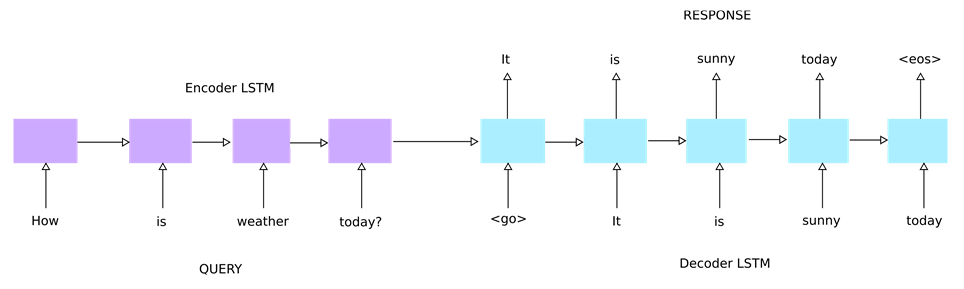
For a long time, AIGC has been dominated by the RNN-based Seq2Seq model which consists of two RNN networks, with the first RNN being the encoder and the second RNN being the decoder. The quality of the text generated by RNN Seq2Seq is usually poor, often accompanied by grammatical errors or unclear semantics, mainly due to error transmission and amplification.
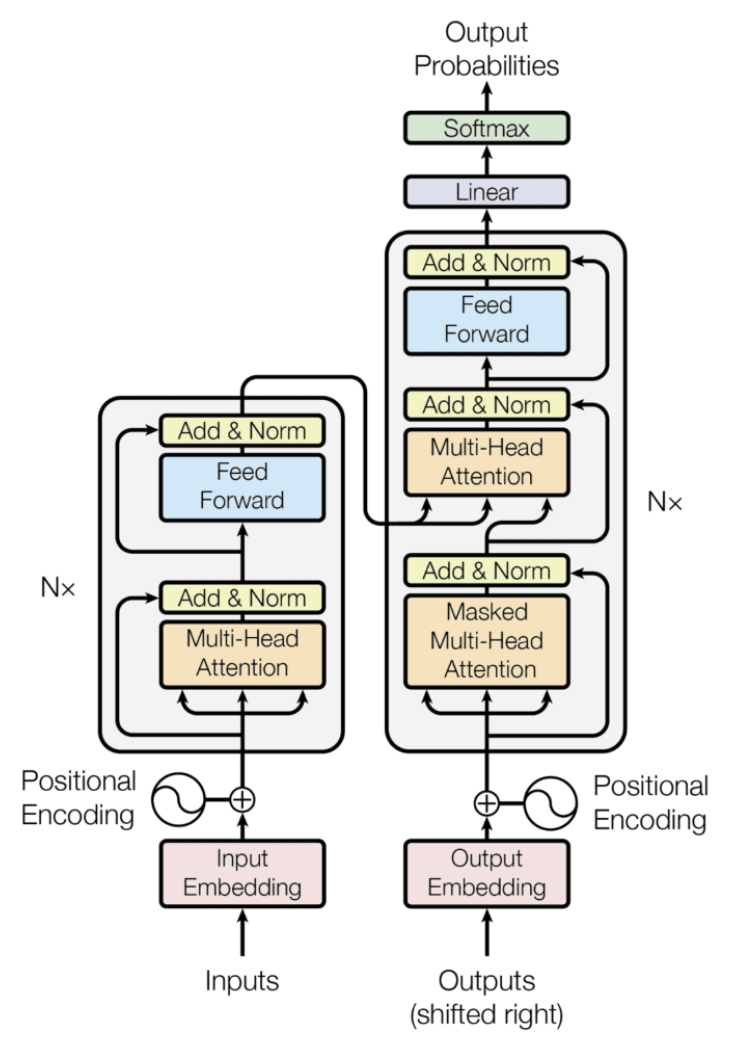
In 2017, the Transformer model structure was introduced and quickly gained popularity due to its ability to capture complex feature representations and its improved training efficiency compared to RNN models. As a result, a series of pre-training models were developed, which have become the leading AIGC technologies. The following section will provide an overview of these models. The Transformer model is particularly useful because it can process sequences in parallel, leading to a shift in the focus of text-writing algorithm research toward the Transformer model.
UniLM
UniLM, short for Unified Language Model, is a generative BERT model developed by the Microsoft Research Institute in 2019. Unlike traditional Seq2Seq models, it only utilizes BERT and does not have a Decoder component. It combines the training methods of several other models, such as L2R-LM (ELMo, GPT), R2L-LM (ELMo), BI-LM (BERT), and Seq2Seq-LM, hence the name “Unified” model.

UniLM’s pre-training is divided into three parts: Left-to-Right, Bidirectional, and Seq-to-Seq.
The difference between these three methods is only in the change of the Transformer’s mask matrix:
- For Seq-to-Seq, the Attention of the previous sentence is masked for the following sentence, so that the previous sentence can only focus on itself but not the following sentence; the Attention of each word in the following sentence to its subsequent words is masked, and it can only focus on the words before it;
- For Left-to-Right, the Transformer’s Attention only focuses on the word itself and the words before it and does not pay attention to the words after it, so the mask matrix is a lower triangle matrix;
- For Bidirectional, the Transformer’s Attention pays attention to all words and includes the NSP task, just like the original BERT.
In the UniLM pre-training process, each of these three methods is trained for 1/3 of the time. Compared to the original BERT, the added unidirectional LM pre-training enhances the text representation ability, and the added Seq-to-Seq LM pre-training also enables UniLM to perform well in text generation/writing tasks.
T5
T5, whose full name is Text-to-Text Transfer Transformer, is a model structure proposed by Google in 2020 with the general idea of using Seq2Seq text generation to solve all downstream tasks: e.g., Q&A, summarization, classification, translation, matching, continuation, denotational disambiguation, etc. This approach enables all tasks to share the same model, the same loss function, and the same hyperparameters.
The model structure of T5 is an Encoder-Decoder structure based on a multilayer Transformer. The main difference between T5 and the other models is that the GPT family is an autoregressive language model (AutoRegressive LM) containing only the Decoder structure, and BERT is a self-coding language model (AutoEncoder LM) containing only the Encoder.

The pre-training of T5 is divided into two parts, unsupervised and supervised.
- Unsupervised training
The unsupervised part is the MLM method similar to BERT, except that BERT is masking a single word, while T5 is masking a segment of consecutive words, i.e., text span. the text span being masked is only replaced by a single mask character, i.e., the sequence length of the mask is also unknown for the post-mask text. In the Decoder part, only the text span of the mask is output, and the other words are replaced by the set , , and symbols uniformly. This has three advantages, one is that it increases the difficulty of pre-training, obviously predicting a continuous text span of unknown length is a more difficult task than predicting a single word, which also makes the text representation capability of the trained language model more universal and more adaptable to fine-tuning on poor quality data; the second is that for the generation task the output sequence is of unknown length, and the pre-training of T5 is well This pre-training task used in T5 is also known as CTR (Corrupted Text Reconstruction).
- Supervised training
The supervised part uses the four major categories of tasks included in GLUE and SuperGLUE: machine translation, question and answer, summarization, and classification. The core of Fine-tune is to combine these datasets and tasks together as one task, and in order to achieve this it is thought to design a different prefix for each task, which is input together with the task text. For example, for the translation task, to translate “That is good.” from English to German, then “translate English to German: That is good. target: Das ist gut.” is entered for training, and “translate English to German: That is good. target:”, and the model output predicts “Das ist gut.”. where “translate English to German:” is the prefix added for this translation task.
BART
BART stands for Bidirectional and Auto-Regressive Transformers. It is a model structure proposed by Facebook in 2020. As its name suggests, it is a model structure that combines a bidirectional encoding structure with an auto-regressive decoding structure. The BART model structure absorbs the characteristics of the Bidirectional Encoder in BERT and the Left-to-Right Decoder in GPT, building on the standard Seq2Seq Transformer model, which makes it more suitable for text generation scenarios than BERT. At the same time, compared to GPT, it also has more bidirectional contextual context information.

The pre-training task of BART adopts the basic idea of restoring the [noise] in the text. BART uses the following specific [noise]:
- Token Masking: As with BERT, randomly select a token to be replaced with [MASK];
- Token Deletion: Randomly delete a token and the model must determine which input is missing;
- Text Infilling: Similar to the T5 approach, mask a text span and each text span is replaced by a [MASK] tag.
- Sentence Permutation: Divide the input into multiple sentences using the period as a separator and randomly shuffle them;
- Document Rotation: Randomly and uniformly select a token and rotate the input around it with the selected token as the new beginning, this task trains the model to recognize the beginning of a document.
It can be seen that compared to BERT or T5, BART tries various [noise] on the Encoder side, and the reason and purpose are also simple:
- The simple replacement used in BERT results in the Encoder input carrying some information about the sequence structure (such as the length of the sequence), which is generally not provided to the model in text generation tasks.
- BART uses a more diverse set of [noise] with the intention of destroying this information about the sequence structure and preventing the model from “relying” on it. For various input [noise], BART uses a unified reconstruction form on the Decoder side, i.e. outputting the correct original sentence. The pre-training task used by BART is also known as FTR (Full-Text Reconstruction).
GPT
GPT stands for Generative Pre-Training. It is an iterative pre-training model, and its family of main members includes the first-generation GPT, GPT-2, GPT-3, InstructGPT, and the currently popular ChatGPT. Here we introduce them one by one.
GPT-1
The first-generation GPT is a pre-trained language model proposed by OpenAI in 2018. Its birth was earlier than BERT, and its core idea is to perform generative pre-training learning based on a large amount of unannotated data, and then fine-tune it on specific tasks. Because it focuses on generative pre-training, the GPT model structure only uses the Decoder part of the Transformer, and its standard structure includes Masked Multi-Head Attention and Encoder-Decoder Attention. The pre-training task of GPT is SLM (Standard Language Model), which predicts the current position of the word based on the previous context (window), so it is necessary to retain the Mask Multi-Head Attention to block the following context of the word to prevent information leakage. Because the Encoder is not used, Encoder-Decoder Attention is removed from the GPT structure.
GPT-2
The problem with the first-generation GPT is that the fine-tuning downstream task lacks transferability and the Fine-Tuning layer is not shared. In order to solve this problem, OpenAI introduced a new member of the GPT family in 2019: GPT-2.
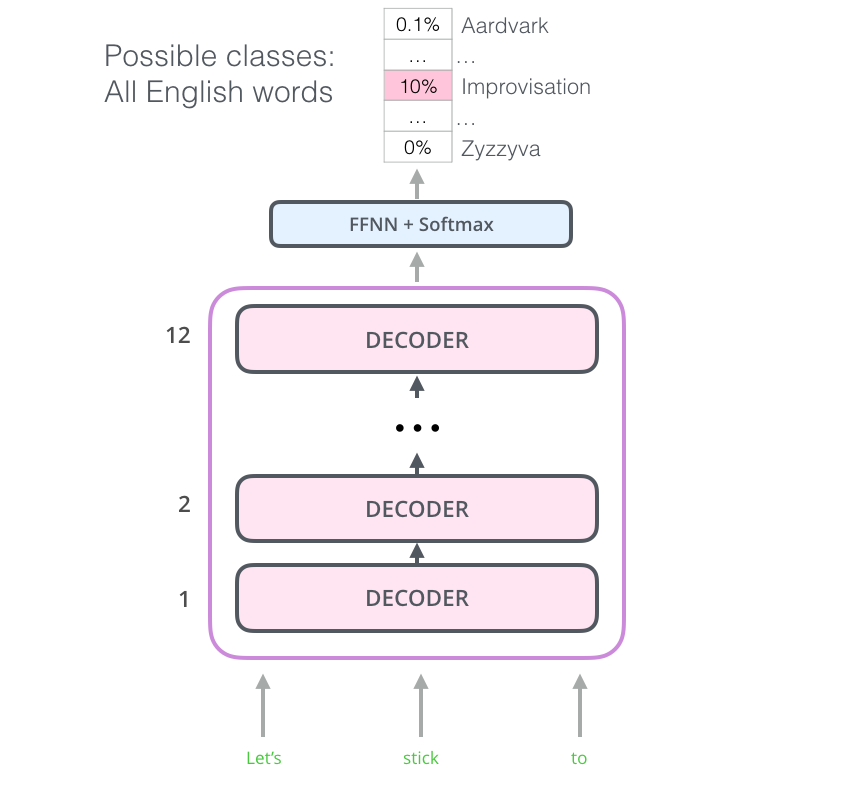
The learning goal of GPT-2 is to use an unsupervised pre-trained model to do a supervised task. Compared to the first-generation GPT, GPT-2 has the following changes:
- the model structure removes the Fine-Tuning layer, and all tasks are pre-trained by designing reasonable statements for the language model, and the training needs to ensure that the loss function of each task converges;
- the position of Layer Normalization is moved to the input of each sub-block, and a Layer Normalization is also added after the last Self-Attention;
- a modified initialization method is used, in which the weights of the residual layer are scaled to 1/√N times at initialization, where N is the number of residual layers;
- the Vocabulary scale is expanded to 50257, the size of the input context is expanded from 512 to 1024, and a larger batch_size is used for training. The multi-task training of GPT-2 makes it a stronger generalization ability, of course, this is also due to its use of up to 40G of the training corpus. The biggest contribution of GPT-2 is to verify that the model trained with massive data and a large number of parameters has the ability to transfer to other category tasks without additional training.
GPT-3
In 2020, OpenAI further introduced GPT-3 based on GPT-2. GPT-3’s approach is simpler and rougher, and the overall structure and training goals of the model are similar to GPT-2, but GPT-3 increases the model size to 175 billion parameters (115 times larger than GPT-2) and uses 45TB of data for training. Thanks to the staggering number of parameters, GPT-3 can learn and predict using zero-sample and few-sample without gradient updates.
InstructGPT
The super large model GPT-3 has indeed achieved unprecedented results in generating tasks, especially in zero-sample and few-sample scenarios, but GPT-3 has faced a new challenge: the output of the model is not always useful, it may output results that are not real, harmful or reflect negative emotions. This phenomenon is understandable because the pre-trained task is a language model and the goal of pre-training is to maximize the likelihood of the output being natural language under the input constraints, without the requirement of “user needs safety and usefulness”. To solve this problem, in 2022 OpenAI published important research based on GPT-3: InstructGPT, introducing the technology of reinforcement learning from human feedback (RLHF).

InstructGPT has not changed much from GPT-3 in terms of the model itself, the main change is in the training strategy. The overall idea is to have annotators provide demonstration answers for the call examples, and then use this data to fine-tune the model so that it can make more appropriate responses. Its training steps are divided into three steps:
- Collect demonstration data and train a model using supervised training. Sample a portion of the prompt dataset for manual annotation and use it for Fine-Tuning GPT-3.
- Collect contrast data and train a reward model. Sample a batch of data and input it into the model fine-tuned in step 1. Annotators rank the model’s output according to its merit and use this data to train a reward model.
- Use reinforcement learning to optimize the model’s output. Use the reward model obtained in step 2 to optimize the output of the model fine-tuned in step 1 through reinforcement learning, so that the model can output more appropriate responses.
The resulting InstructGPT is much better than GPT-3 in terms of following instructions, and also InstructGPT is less likely to make up facts out of thin air, with a small downward trend in the production of harmful outputs.
ChatGPT
ChatGPT, the latest research officially released by OpenAI on November 30, 2022, uses the same approach as InstructGPT, using reinforcement learning from human feedback (RLHF) to train the model, with improvements in the data collection method (not specifically disclosed).

As can be seen, the training process of ChatGPT is consistent with that of InstructGPT, the difference is that InstructGPT fine-tunes on GPT-3, while ChatGPT fine-tunes on GPT-3.5 (GPT-3.5 is a model trained by OpenAI in Q4 2021 with strong ability in automatic code writing).
Throughout the development from the first-generation GPT to ChatGPT, OpenAI has proved that using super large data to train super large models, the resulting pre-trained language model is sufficient to handle various downstream tasks of natural language understanding and natural language generation, even without fine-tuning, and can still handle zero/few-sample tasks. In terms of the safety and controllability of the output, OpenAI’s answer is based on human-powered reinforcement learning: hiring 40 full-time annotators to work for nearly 2 years (the annotation time was not officially disclosed, the author only inferred from the roughly two and a half years interval between GPT-3 and ChatGPT, because reinforcement learning requires continuous iteration) to provide annotation feedback for the model’s output, and only with this data can reinforcement learning be performed to guide the optimization of the model. Transformer + super large data + super large model + massive human power + reinforcement learning has created the phenomenal ChatGPT of today.
About DTonomy
Our company specializes in developing AI applications and bringing AI to help teams, particularly IT support centers, quickly respond to issues or customer requests. Whether through custom development or AI-based product, we are committed to helping our clients stay ahead of the curve and stay protected.
When you are ready, here are things we can help:
Schedule a free consultation to discover how to integrate ChatGPT into your product or workflow leveraging ChatGPT API (schedule here).
Here is service brochure provided by our subsidiary company:

